Web scraping is used in a wide variety of applications today. For example, e-commerce companies use web scraping to gather pricing data, product descriptions and reviews from other e-commerce websites. Similarly, online travel agents such as Expedia, Booking.com, etc., scrape hotel rates and other details from their suppliers’ websites to display them on their own sites and compare the prices of different hotels and airlines.
Many organizations also use web scraping techniques to monitor price changes for products sold online and track their competitors’ prices. Companies that have large collections of stores or branches use web scraping to collect data from all branches to understand sales trends and make decisions accordingly.
Table of Contents
Best Chrome Extension For Web Scraping
Scrapy

Scrapy is an open source web scraping framework in Python used to build web scrapers. It gives you all the tools you need to efficiently extract data from websites, process them, and store them in your preferred structure and format. One of its main advantages is that it’s built on top of a Twisted asynchronous networking framework. If you have a large data scraping project and want to make it as efficient as possible with a lot of flexibility then you should definitely use this data scraping tool. You can export data into JSON, CSV and XML formats. What stands out about Scrapy is its ease of use, detailed documentation, and active community. It runs on Linux, Mac OS, and Windows systems.
ScrapeHero Cloud

ScrapeHero Cloud is a browser based web scraping platform. ScrapeHero has used its years of experience in web crawling to create affordable and easy to use pre-built crawlers and APIs to scrape data from websites such as Amazon, Google, Walmart, and more. The free trial version allows you to try out the scraper for its speed and reliability before signing up for a plan.
ScrapeHero Cloud DOES NOT require you to download any data scraping tools or software and spend time learning to use them. It is a browser based web scraper which can be used from any browser. You don’t need to know any programming skills or need to build a scraper, it is as simple as click, copy, paste and go !
In three steps you can set up a crawler – Open your browser, Create an account in ScrapeHero Cloud and select the crawler that you wish to run. Running a crawler in ScrapeHero Cloud is simple and requires you to provide the inputs and click “Gather Data” to run the crawler.
ScrapeHero Cloud crawlers allow you to to scrape data at high speeds and supports data export in JSON, CSV and Excel formats. To receive updated data, there is the option to schedule crawlers and deliver data directly to your Dropbox.
All ScrapeHero Cloud crawlers come with auto rotate proxies and the ability to run multiple crawlers in parallel. This allows you to scrape data from websites without worrying about getting blocked in a cost effective manner.
ScrapeHero Cloud provides Email support to it’s Free and Lite plan customers and Priority support to all other plans.
ScrapeHero Cloud crawlers can be customized based on customer needs as well. If you find a crawler not scraping a particular field you need, drop in an email and ScrapeHero Cloud team will get back to you with a custom plan.Get Started for FREE !Scrape data using ScrapeHero Cloud:
- Scrape Amazon Reviews
- Scrape Amazon BestSeller Listings
- Scrape Historical Twitter Data
- Scrape product data and prices from Walmart
Data Scraper

Data Scraper is a simple and free web scraping tool for extracting data from a single page into CSV and XSL data files. It is a personal browser extension that helps you transform data into a clean table format. You will need to install the plugin in a Google Chrome browser. The free version lets you scrape 500 pages per month, if you want to scrape more pages you have to upgrade to the paid plans.Overview of Data Scraper
Scraper

Scraper is a chrome extension for scraping simple web pages. It is a free web scraping tool which is easy to use and allows you to scrape a website’s content and upload the results to Google Docs or Excel spreadsheets. It can extract data from tables and convert it into a structured format. Overview of Scraper
Parsehub
ParseHub is a web based data scraping tool which is built to crawl single and multiple websites with the support for JavaScript, AJAX, cookies, sessions, and redirects. The application can analyze and grab data from websites and transform it into meaningful data. It uses machine learning technology to recognize the most complicated documents and generates the output file in JSON, CSV , Google Sheets or through API.
Parsehub is a desktop app available for Windows, Mac, and Linux users and works as a Firefox extension. The easy user-friendly web app can be built into the browser and has a well written documentation. It has all the advanced features like pagination, infinite scrolling pages, pop-ups, and navigation. You can even visualize the data from ParseHub into Tableau.
The free version has a limit of 5 projects with 200 pages per run. If you buy Parsehub paid subscription you can get 20 private projects with 10,000 pages per crawl and IP rotation.Overview of ParseHub
OutWitHub
OutwitHub is a data extractor built in a web browser. If you wish to use the software as an extension you have to download it from Firefox add-ons store. If you want to use the data scraping tool you just need to follow the instructions and run the application. OutwitHub can help you extract data from the web with no programming skills at all. It’s great for harvesting data that might not be accessible.
OutwitHub is a free web scraping tool which is a great option if you need to scrape some data from the web quickly. With its automation features, it browses automatically through a series of web pages and performs extraction tasks. The data scraping tool can export the data into numerous formats (JSON, XLSX, SQL, HTML, CSV, etc.).
Visual Web Ripper
Visual Web Ripper is a website scraping tool for automated data scraping. The tool collects data structures from pages or search results. Its has a user friendly interface and you can export data to CSV, XML, and Excel files. It can also extract data from dynamic websites including AJAX websites. You only have to configure a few templates and web scraper will figure out the rest. Visual Web Ripper provides scheduling options and you even get an email notification when a project fails.
Import.io
With Import.io you can clean, transform and visualize the data from the web. Import.io has a point to click interface to help you build a scraper. It can handle most of the data extraction automatically. You can export data into CSV, JSON and Excel formats.
Import.io provides detailed tutorials on their website so you can easily get started with your data scraping projects. If you want a deeper analysis of the data extracted you can get Import.insights which will visualize the data in charts and graphs.
Diffbot
The Diffbot application lets you configure crawlers that can go in and index websites and then process them using its automatic APIs for automatic data extraction from various web content. You can also write a custom extractor if automatic data extraction API doesn’t work for the websites you need. You can export data into CSV, JSON and Excel formats.
Octoparse
Octoparse is a visual website scraping tool that is easy to understand. Its point and click interface allows you to easily choose the fields you need to scrape from a website. Octoparse can handle both static and dynamic websites with AJAX, JavaScript, cookies and etc. The application also offers advanced cloud services which allows you to extract large amounts of data. You can export the scraped data in TXT, CSV, HTML or XLSX formats.
Octoparse’s free version allows you to build up to 10 crawlers, but with the paid subscription plans you will get more features such as API and many anonymous IP proxies that will faster your extraction and fetch large volume of data in real time.
how to use web scraper chrome extension
Web scraping is becoming a vital ingredient in business and marketing planning regardless of the industry. There are several ways to crawl the web for useful data depending on your requirements and budget. Did you know that your favourite web browser could also act as a great web scraping tool?
You can install the Web Scraper extension from the chrome web store to make it an easy-to-use data scraping tool. The best part is, you can stay in the comfort zone of your browser while the scraping happens. This doesn’t demand much technical skills, which makes it a good option when you need to do some quick data scraping. Let’s get started with the tutorial on how to use web scraper chrome extension to extract data.
About the Web Scraper Chrome Extension
Web Scraper is a web data extractor extension for chrome browsers made exclusively for web data scraping. You can set up a plan (sitemap) on how to navigate a website and specify the data to be extracted. The scraper will traverse the website according to the setup and extract the relevant data. It lets you export the extracted data to CSV. Multiple pages can be scraped using the tool, making it even more powerful. It can even extract data from dynamic pages that use Javascript and Ajax.
What You Need
- Google Chrome browser
- A working internet connection
A. Installation and setup
- webscraper chrome extension by using link
- For web scraper chrome extension download click on “Add”
Once this is done, you are ready to start scraping any website using your chrome browser. You just need to learn how to perform the scraping, which we are about to explain.
B. The Method
After installation, open the Google Chrome developer tools by pressing F12. (You can alternatively right-click on the screen and select inspect element). In the developer tools, you will find a new tab named ‘Web scraper’ as shown in the screenshot below.
Now let’s see how to use this on a live web page. We will use a site called www.awesomegifs.com for this tutorial. This site contains gif images and we will crawl these image URLs using our web scraper.
Step 1: Creating a Sitemap
- Go to https://www.awesomegifs.com/
- Open developer tools by right-clicking anywhere on the screen and then selecting inspect
- Click on the web scraper tab in developer tools
- Click on ‘create new sitemap’ and then select ‘create sitemap’
- Give the sitemap a name and enter the URL of the site in the start URL field.
- Click on ‘Create Sitemap’
To crawl multiple pages from a website, we need to understand the pagination structure of that site. You can easily do that by clicking the ‘Next’ button a few times from the homepage. Doing this on Awesomegifs.com revealed that the pages are structured as https://awesomegifs.com/page/1/, https://awesomegifs.com/page/2/, and so on. To switch to a different page, you only have to change the number at the end of this URL. Now, we need the scraper to do this automatically.
To do this, create a new sitemap with the start URL as https://awesomegifs.com/page/[001-125]. The scraper will now open the URL repeatedly while incrementing the final value each time. This means the scraper will open pages starting from 1 to 125 and crawl the elements that we require from each page.
Step 2: Scraping Elements
Every time the scraper opens a page from the site, we need to extract some elements. In this case, it’s the gif image URLs. First, you have to find the CSS selector matching the images. You can find the CSS selector by looking at the source file of the web page (CTRL+U). An easier way is to use the selector tool to click and select any element on the screen. Click on the Sitemap that you just created, click on ‘Add new selector’. In the selector id field, give the selector a name. In the type field, you can select the type of data that you want to be extracted. Click on the select button and select any element on the web page that you want to be extracted. When you are done selecting, click on ‘Done selecting’. It’s easy as clicking on an icon with the mouse. You can check the ‘multiple’ checkbox to indicate that the element you want can be present multiple times on the page and that you want each instance of it to be scrapped.
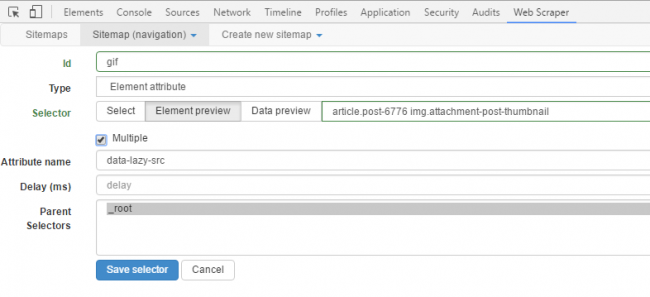
Now you can save the selector if everything looks good. To start the scraping process, just click on the sitemap tab and select ‘Scrape’. A new window will pop up which will visit each page in the loop and crawl the required data. If you want to stop the data scraping process in between, just close this window and you will have the data that was extracted till then.
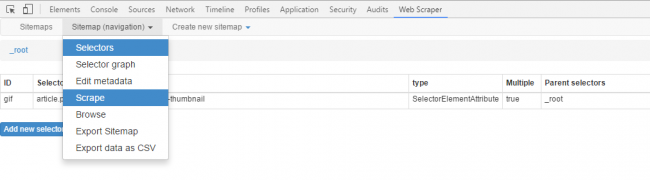
Once you stop scraping, go to the sitemap tab to browse the extracted data or export it to a CSV file. The only downside of such data extraction software is that you have to manually perform the scraping every time since it doesn’t have many automation features built-in.
If you want to crawl data on a large scale, it is better to go with a data scraping service instead of such free web scraper chrome extension data extraction tools like these. With the second part of this series, we will show you how to make a MySQL database using the extracted data. Stay tuned for that!
Conclusion
Let us know your thoughts in the comment section below.
Check out other publications to gain access to more digital resources if you are just starting out with Flux Resource.
Also contact us today to optimize your business(s)/Brand(s) for Search Engines